2021. 9. 26. 23:21ㆍAI 온라인 교육/데이터 분석을 위한 라이브러리
데이터 프레임 정렬하기
Index 값 기준으로 정렬
- sort_index() 사용
df = df.sort_index(axis=0)
* axis=0: 행 인덱스 기준 정렬(Default 오름차순)
axis=1: 열 인덱스(column) 내림차순 정렬
df= df.sort_index(axis=1, ascending=False)
* True: 오름차순
False: 내림차순
Column 값 기준으로 정렬
col1 컬럼 기준 정렬(Default 오름차순)
- sort_values() 사용

col1 컬럼 기준 내림차순 정렬

col2컬럼 기준 오름차순 정렬 후 col1컬럼 기준 내림차순 정렬
형식:
sort_values([먼저 정렬할 column, 나중에 정렬할 column], ascending=[정렬방법, 정렬방법])

# col2의 오름차순을 순서를 방해하지 않으면서 col1을 내림차순함
집계 함수(Default: NaN값 제외)
count(데이터 타입: int)
: count 메서드 활용하여 데이터 개수 확인 가능

max(데이터 타입: float)
: max 메서드 활용하여 최대값 확인 가능

min(데이터 타입: float)
: min 메서드 활용하여 최소값 확인 가능

sum(데이터 타입: float)
: sum 메서드 활용하여 합계 계산

mean(데이터 타입: float)
: mean 메서드 활용하여 평균 계산

sum, mean => axis, skipna인자 활용해 합계 및 평균 계산(행기준, NaN값 포함시)


# skipna: 값이 없는게 있으면 skip할건지 무시할건지
False는 반환/True 반환 X
NaN값이 존재하는 column의 평균을 구하여 NaN값 대체

#skipna는 NaN이 없으므로 딱히 의미 없음

그룹으로 묶기
group by
: 간단한 집계를 넘어서서 조건부로 집계하고 싶은 경우
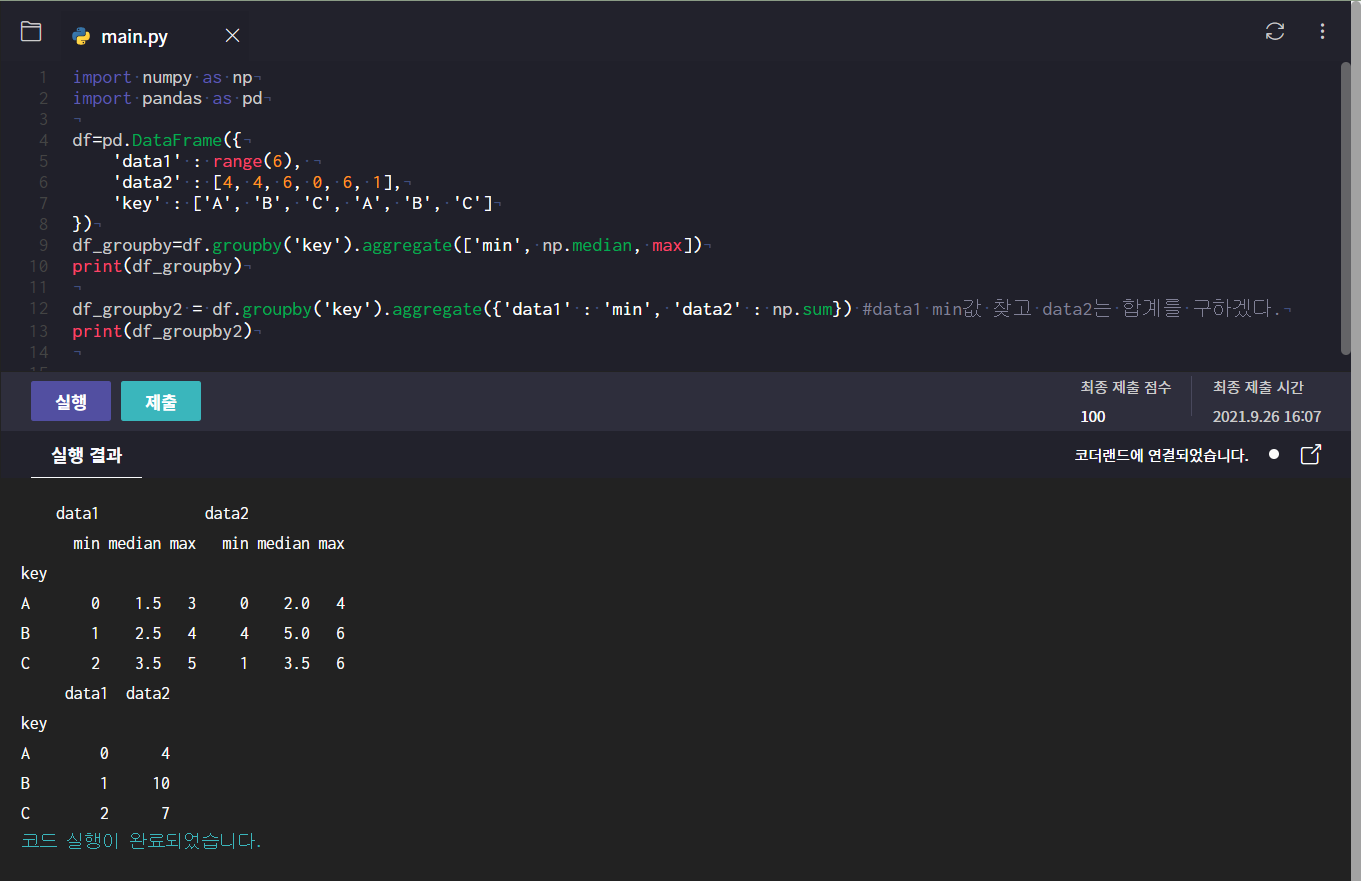
aggregate
: groupby를 통해서 집계를 한번에 계산하는 방법
filter
: groupby를 통해서 그룹 속성을 기준으로 데이터 필터링

apply, lambda
: groupby를 통해서 묶인 데이터에 함수 적용

* apply 함수: 데이터 프레임에 특정 함수를 '적용'시키는 함수
lambda 함수: 한 번 쓰고 버리는 함수
get_group
: groupby 로 묶인 데이터에서 key값으로 데이터를 가져올 수 있다.
df= pd.read_csv("//univ.csv")
#상위 5개 데이터
df.head()
#데이터 추출
df.groupby("시도").get_group("충남") #groupby를 통해서 시도를 묶고 get_group으로 충남의 데이터를 가져와
len(df.groupby("시도").get_group("충남)) #len을 이용해 데이터 길이를 알 수 있다.
'AI 온라인 교육 > 데이터 분석을 위한 라이브러리' 카테고리의 다른 글
| 05. Matplotlib 데이터 시각화 (0) | 2021.09.29 |
|---|---|
| 03. Pansdas (0) | 2021.09.25 |
| 02. Numpy (0) | 2021.09.23 |
| 01. 모듈&패키지 (0) | 2021.09.22 |