2021. 9. 23. 23:45ㆍAI 온라인 교육/데이터 분석을 위한 라이브러리
Numpy(Numercal Python )
: Python에서 대규모 다차원 배열을 다룰 수 있게 도와주는 라이브러리
(대표적으로 Pandas, Numpy, matplotlib)
Numpy를 사용하는 이유
- 데이터의 대부분은 숫자배열로 볼수있다. 그렇기 때문에 데이터를 배열로 보고 처리하기 위해서
- 반복문 없이 배열 처리 가능 -> 대용량의 데이터를 빨리 계산 가능
-> 메모리 효율적 사용
Numpy 사용법

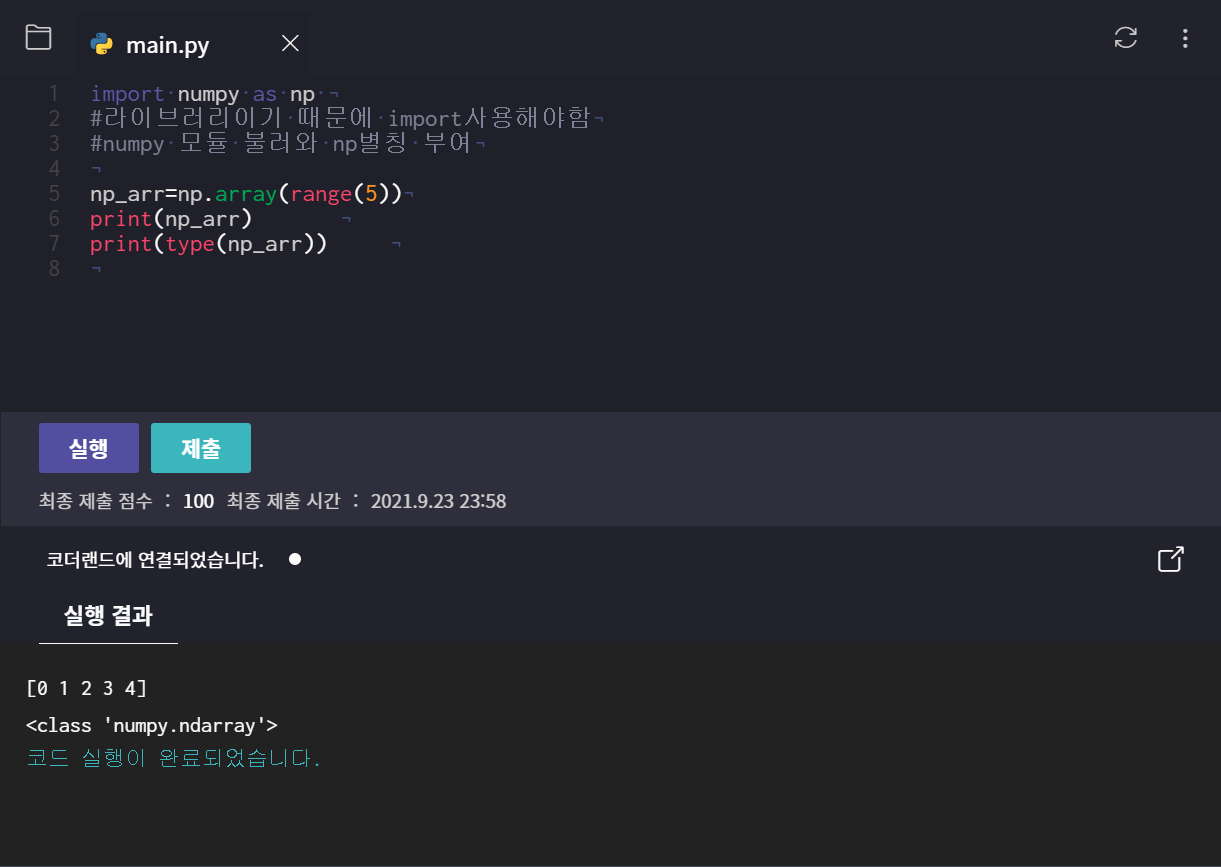
list는 [0, 1, 2, 3, 4, 5] => ,로 구분, 배열은 [0 1 2 3 4 5] => 공백으로 구분
[dtype]
: 배열의 데이터 타입
- 파이썬 리스트와 달리 같은 데이터 타입만 저장가능 -> 단일데이터

dtype종류(숫자는 그 테이터를 저장할수 있는 용량을 말함)
- int 정수형 타입: i, int_, int32, int64,= i8
- float 실수형 타입: f, float_= float64=f8, float32
- str 문자열 타입: str, U(unicode약자), U32
- bool 부울 타입: ?, bool_
ndarray의 차원 관련 속성
- ndim(n+dimensim): 몇차원인지 출력
- shape: 배열의 모양을 출력
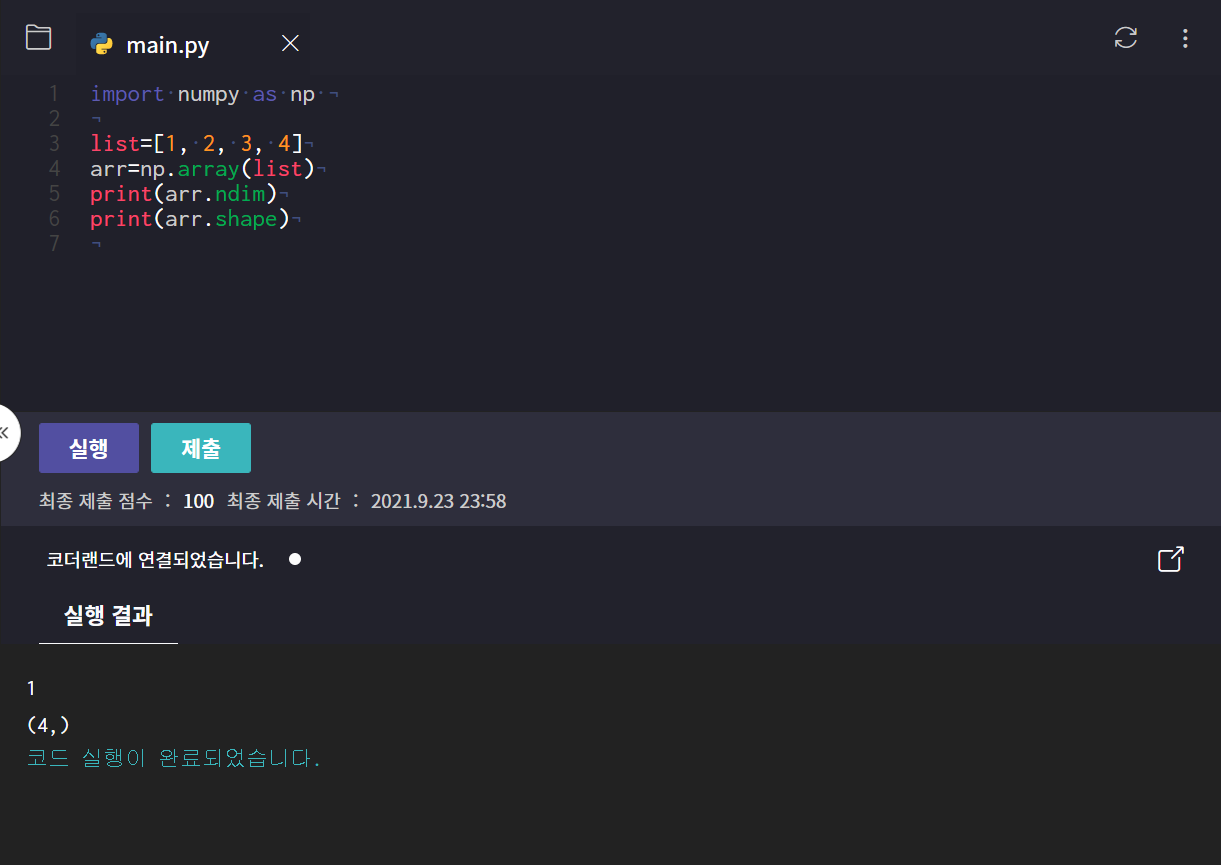

ndarray는 크기속성과 shape조절


* 형태 :'{인덱스0}, {인덱스1}'.format(값0, 값1)
.format 함수의 인자로 순서대로 변수를 넣는다.
[Indexing]
: 인덱스로 값을 찾아냄


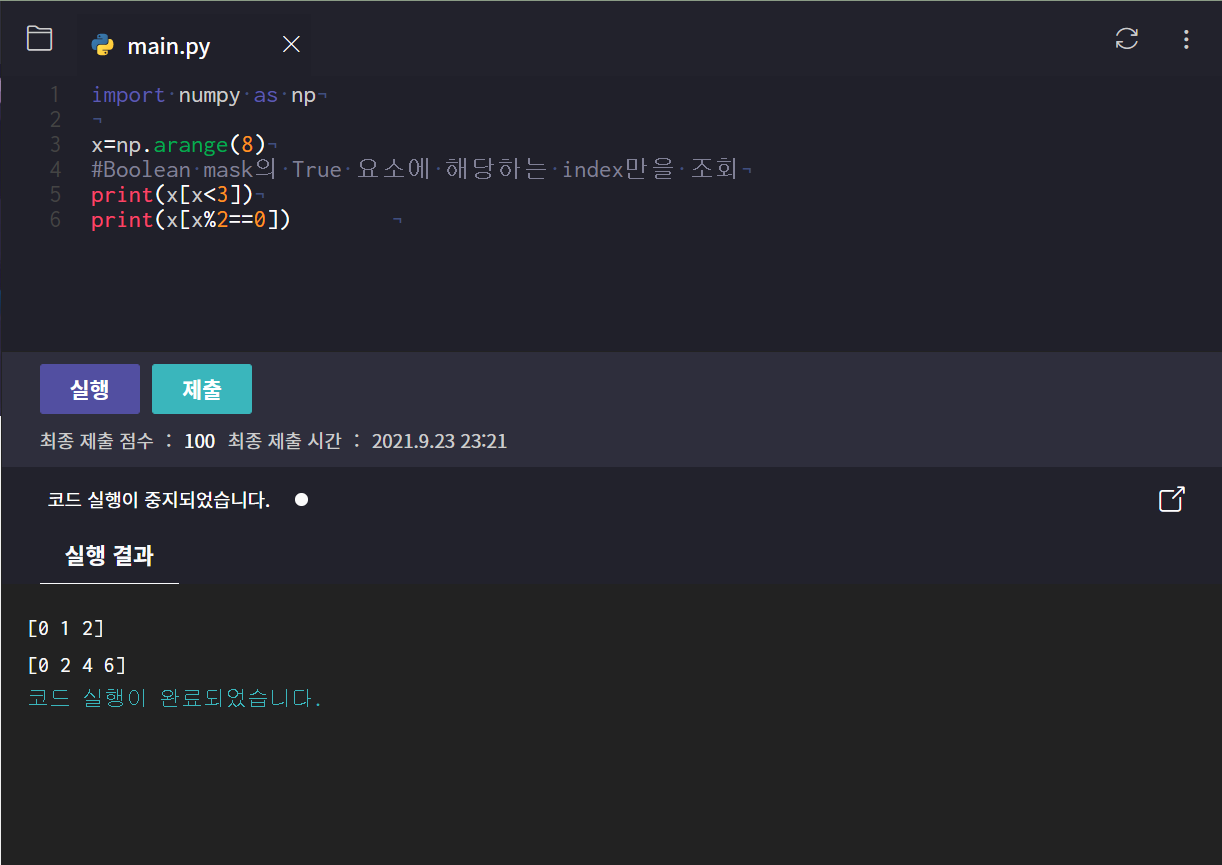
Boolean indexing
: 배열의 각 요소의 선택여부를 Boolean mask(True, False로 구성된 mask array)를 이용하여 지정하는 방식
- 조건에 맞는 데이터를 가져온다
- 참인지 거짓인지 알려준다.

Fancy indexing
:배열의 각 요소 선택을 Index 배열을 전달해 지정하는 방식(찾고 싶은 자리 = 인덱스에 어떤값?)


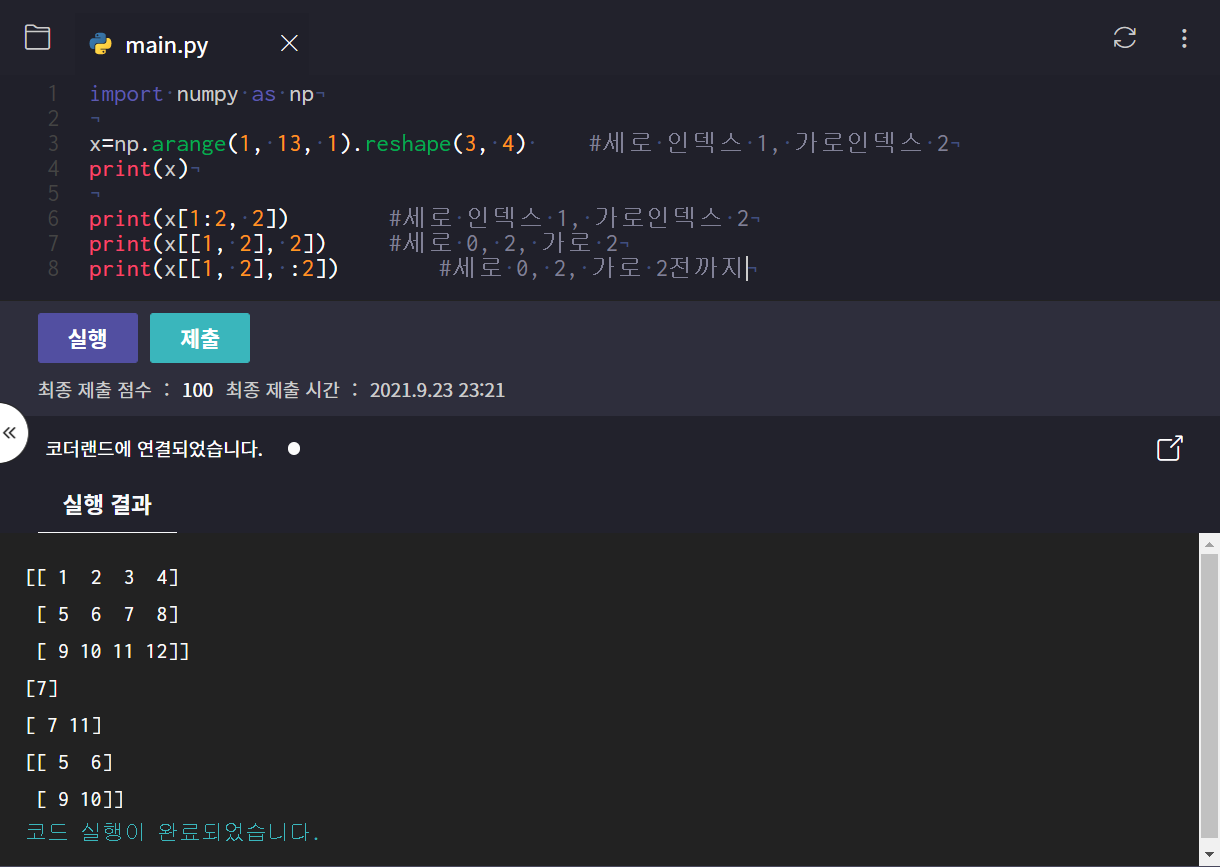
[slicing]
:인덱스의 값으로 배열의 일부분을 가져옴


Indexing&Slicing 함께 활용해보기
'AI 온라인 교육 > 데이터 분석을 위한 라이브러리' 카테고리의 다른 글
| 05. Matplotlib 데이터 시각화 (0) | 2021.09.29 |
|---|---|
| 04. Pandas 심화 (0) | 2021.09.26 |
| 03. Pansdas (0) | 2021.09.25 |
| 01. 모듈&패키지 (0) | 2021.09.22 |