2021. 9. 25. 23:56ㆍAI 온라인 교육/데이터 분석을 위한 라이브러리
Pansdas
: 구조화된 데이터를 효과적으로 처리하고 저장하는 파이썬 라이브러리
- 대용량 데이터를 쉽게 처리할수 있는 Numpy를 기반으로 설계
Series
- 특수한 딕셔너리
- Numpy의 array가 보강된 형태
- Data와 index를 가지고 있음(data+index)
- import를 해야함
ex) import pandas as pd
- 값(value)을 ndarray형태로 가지고 있음

print 4번째 줄 -> 데이터 타입 자체는 Series 형태이지만 들어가는 value는 ndarray
- dtype 인자로 데이터 타입을 지정할 수있음

- 인덱스를 지정할 수 있고 인덱스로 접근가능 -> 인덱스로 접근해 요소 변경가능

- Dictionary를 활용해 Series생성가능


# 과일이름은 인덱스로 들어가고 price는 데이터로 들어간다. 기본적으로 int타입이다.
DataFrame
: 여러개의 Series가 모여서 행과 열을 이룬 데이터

# mg라는 키 값에 mg값을 넣고 price 키값에 price값을 넣는다.
# peach, fig, Shinemusket, plum이 index로 들어가고 mg, price가 column을 들어간다.
- Dictionary를 활용하여 DataFrame생성가능(데이터를 정의해논후 DataFrame안에 넣을 수 있다.).

# fruit=fruit.set_index('fruit')
-> index를 세팅하고 fruit의 column을 인덱스화 하겠다는 의미
DataFrame 속성
- DataFrame 속성 확인

- index, columns 이름 지정
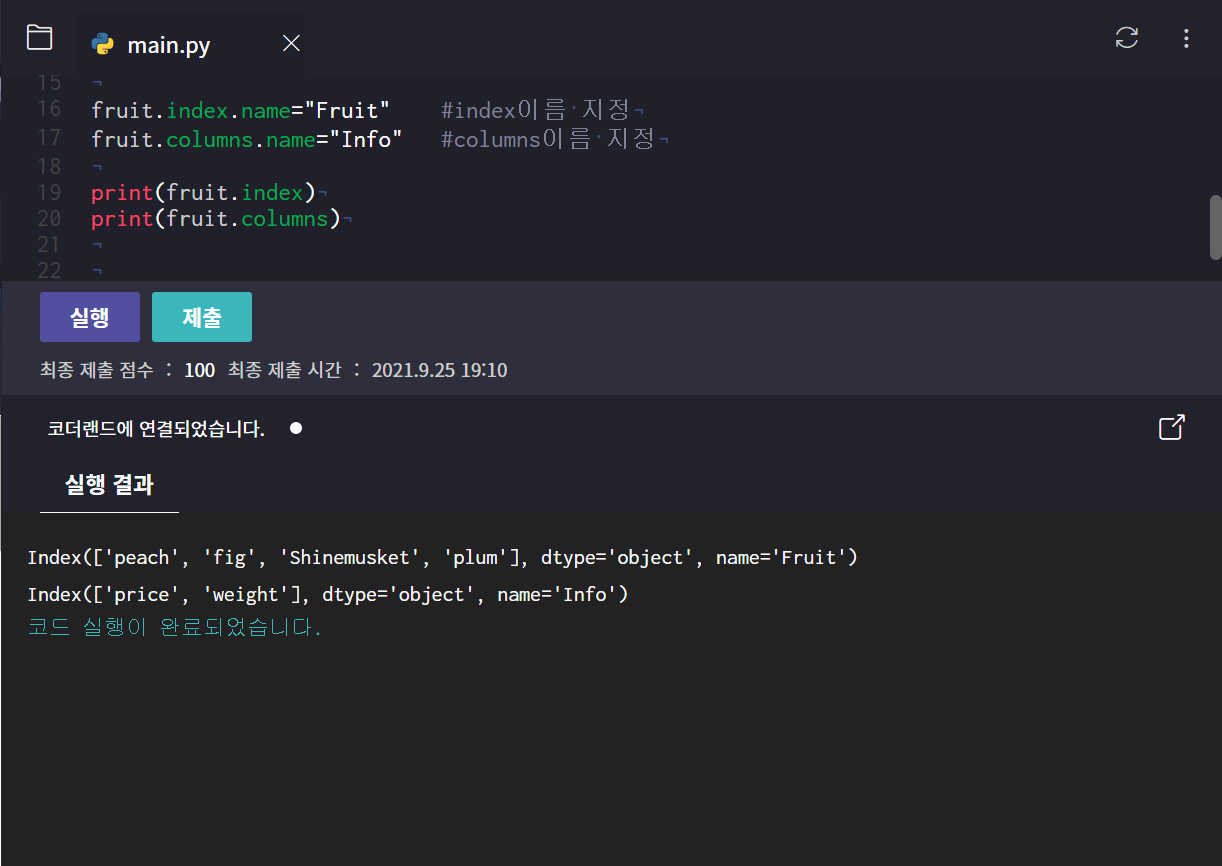
* 문자이므로 " "잘 붙여줘야함
-데이터 프레임 저장
fruit.to_csv("./fruit.csv") #csv = comma separated value = , 구분된 값들
fruit.to_excel("fruit.xlsx") #excel로 저장
- 불러오는 법
fruit=pd.read_csv(./fruit.csv")
fruit=pd.read_excel("fruit.xlsx")
컬럼추가
: Seriese도 numpy array처럼 연산자 활용가능
데이터 추가/수정
: 리스트로 추가 or 딕셔너리로 추가


NaN column 추가
- NaN(not a number: 숫자가 아니다 비어있는 데이터)값으로 초기화한 새로운 column추가

# 0번째 index에 01012345678가 들어가고 데이터가 없으면 NaN출력
컬럼 삭제
- DataFrame에서 컬럼 삭제 후 원본 변경(drop 함수사용)
- 행의 방향(axis=0)으로 삭제할지 열의 방향(axis=1)으로 삭제할지 정해야함
- inplace: 원본을 변경할것인지 정함(True: 원본 변경 O /False: 원본 변경 X)

'AI 온라인 교육 > 데이터 분석을 위한 라이브러리' 카테고리의 다른 글
| 05. Matplotlib 데이터 시각화 (0) | 2021.09.29 |
|---|---|
| 04. Pandas 심화 (0) | 2021.09.26 |
| 02. Numpy (0) | 2021.09.23 |
| 01. 모듈&패키지 (0) | 2021.09.22 |